
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- kotlin
- JVM
- 소프트웨어공학
- flet
- 파이썬
- 자바네트워크
- 데이터베이스
- GPT-4's answer
- write by GPT-4
- jpa
- oracle
- 인프라
- 자바
- 시스템
- 고전역학
- spring data jpa
- 웹 크롤링
- 역학
- android
- Java
- python
- 리눅스
- 유닉스
- NIO
- spring integration
- 자바암호
- write by chatGPT
- Database
- 코틀린
- chatGPT's answer
- Today
- Total
Akashic Records
Spring Data JPA에서 findBy.. 규칙 본문
Spring Data JPA에서는 findBy로 시작하는 메서드 이름을 사용하여 쿼리 메서드를 생성할 수 있습니다. 이를 통해 쉽게 엔티티를 필터링하거나 정렬하는 등의 작업을 수행할 수 있습니다. 메서드 이름만으로도 JPA가 쿼리를 자동으로 생성하므로, 개발자는 직접 쿼리를 작성할 필요가 없습니다.
다음은 findBy 키워드를 사용하는 예시입니다:
public interface UserRepository extends JpaRepository<User, Long> {
// 단일 속성으로 검색
List<User> findByLastName(String lastName);
// 다중 속성으로 검색
List<User> findByFirstNameAndLastName(String firstName, String lastName);
// IgnoreCase 키워드로 대소문자 구분 없이 검색
List<User> findByFirstNameIgnoreCase(String firstName);
// OrderBy 키워드로 정렬
List<User> findByLastNameOrderByFirstNameAsc(String lastName);
// Like 키워드로 부분 일치 검색
List<User> findByLastNameLike(String lastName);
// Between 키워드로 범위 검색
List<User> findByAgeBetween(int startAge, int endAge);
}
위의 예시에서는 findBy 뒤에 엔티티의 속성명을 명시하고, 필요한 경우 추가 키워드를 사용하여 검색 조건을 확장하거나 정렬 기능을 추가합니다.
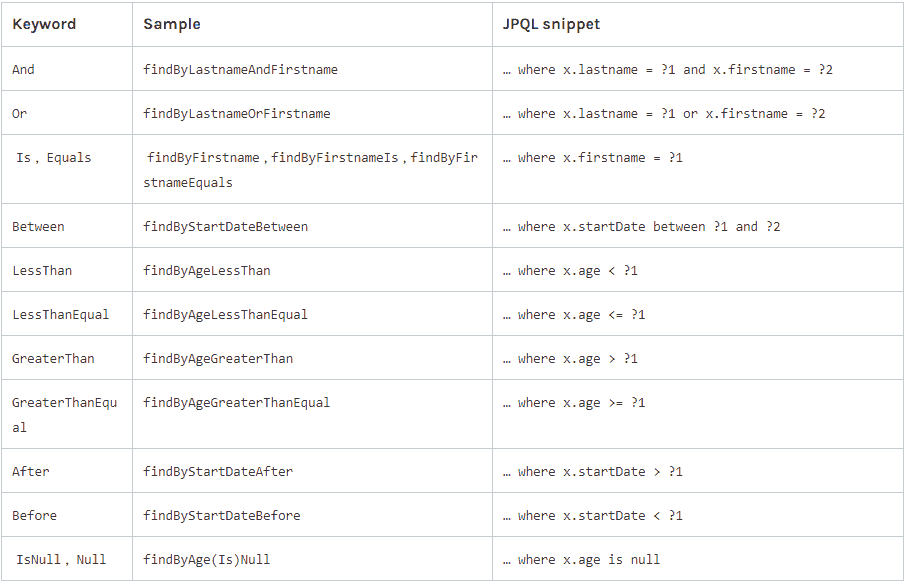
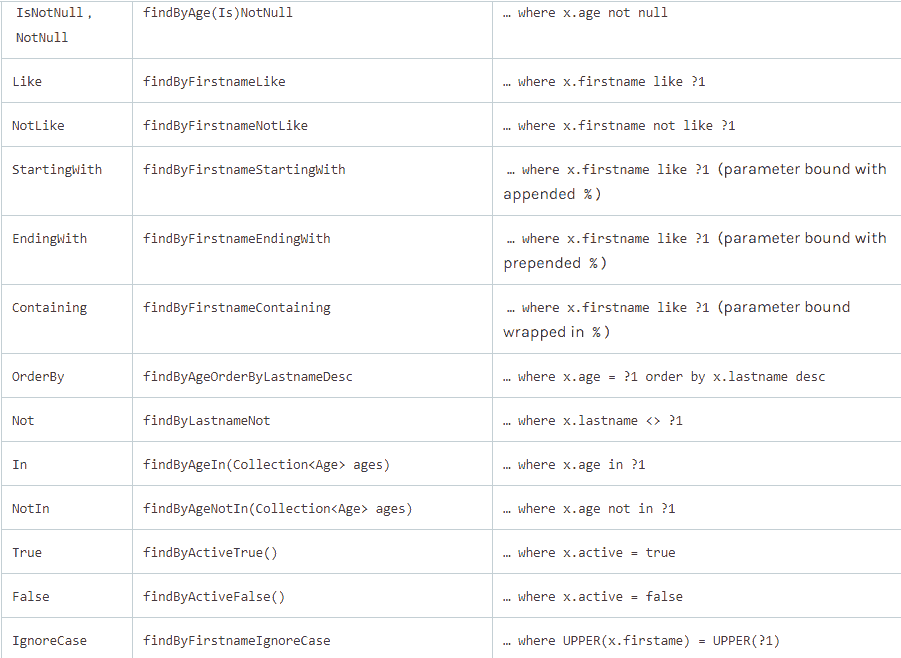
Spring Data JPA는 다양한 키워드를 지원하므로, 복잡한 검색 조건을 지정하는 것도 간단하게 처리할 수 있습니다. 이러한 방식을 사용하면 SQL 쿼리를 작성하지 않아도, 대부분의 일반적인 데이터 검색 요구사항을 만족할 수 있습니다. 하지만 매우 복잡한 쿼리의 경우에는 @Query 어노테이션을 사용하여 직접 JPQL, SQL 쿼리를 작성해야 할 수도 있습니다.
findBy 메서드 이외에도 Spring Data JPA는 다양한 키워드를 사용하여 쿼리를 생성할 수 있습니다. 일부 추가적인 예시들을 살펴보겠습니다.
public interface UserRepository extends JpaRepository<User, Long> {
// Not 키워드로 일치하지 않는 결과 검색
List<User> findByLastNameNot(String lastName);
// GreaterThan, LessThan 키워드로 크기 비교
List<User> findByAgeGreaterThan(int age);
List<User> findByAgeLessThan(int age);
// IsNull, IsNotNull 키워드로 null 값 검색
List<User> findByAddressIsNull();
List<User> findByAddressIsNotNull();
// Top, First 키워드로 결과 갯수 제한
List<User> findTop3ByLastName(String lastName);
List<User> findFirstByLastName(String lastName);
// Distinct 키워드로 중복 제거
List<User> findDistinctByLastName(String lastName);
// CountBy 키워드로 결과 갯수 계산
long countByLastName(String lastName);
}
이렇게 다양한 키워드를 사용하여 쿼리 메서드를 작성할 수 있습니다. 복잡한 쿼리를 작성해야 할 때에는 @Query 어노테이션을 사용하여 직접 JPQL 또는 SQL 쿼리를 작성할 수도 있습니다.
public interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT u FROM User u WHERE u.email = ?1")
User findByEmailAddress(String emailAddress);
@Query(value = "SELECT * FROM users WHERE email = ?1", nativeQuery = true)
User findByEmailAddressNative(String emailAddress);
}위의 예시에서는 @Query 어노테이션을 사용하여 JPQL 및 네이티브 SQL 쿼리를 작성하였습니다. 이를 사용하면 더욱 복잡한 쿼리를 작성할 수 있으며, 성능 최적화를 위해 네이티브 SQL 쿼리를 사용할 수도 있습니다.
Spring Data JPA를 사용하면 간단한 쿼리부터 복잡한 쿼리까지 쉽게 작성할 수 있으며, 개발자의 생산성을 향상시키고 코드의 가독성을 높일 수 있습니다.
'Spring.io' 카테고리의 다른 글
| Spring Data JPA @Query 어노테이션 (0) | 2023.04.10 |
|---|---|
| Spring Data JPA (0) | 2023.04.10 |
| Spring Security, SecurityContextHolder 사용법 (0) | 2023.04.10 |
| Spring jdbc Template의 종류와 사용방법 (0) | 2023.04.10 |
| Spring Batch+Quartz에서 Trigger 삭제하고 등록하기 (0) | 2023.04.06 |



